on
A brief introduction to Download Managers in GoLang
Have you ever wondered how web browsers download anything from the internet? Imagine a scenario in which an application wants to download a large file (Zip file, Video, etc.) from a URL during its execution and perform some operations on the downloaded file. Recently, I encountered this problem while working on a GoLang application.
I wanted a solution that can save the downloaded file to a given file location, resume the download after connection failure, and keep track of the download progress. I was in a bit of a hurry to complete my task, so I decided to use an open-source library (grab) which satisfies the above requirements and supports some more.
This blog post is a step-by-step explanation of the internal workings of a download manager like grab.
Let’s use the following URL:http://www.golang-book.com/public/pdf/gobook.pdf as an example to download a PDF of An Introduction to Programming in Go.
Step#1 - Decide the File Location to store the Downloaded file
- Web Browsers use the
Downloadfolder on the computer to store the downloaded files. - We should give an option to the user to provide the directory/path to store the downloaded file.
- If the user doesn’t provide the directory/path, use the directory where the application code resided.
- If the given directory doesn’t exist, we should create all the missing directories in the path.
func validateDestPath(destinationPath string) (string, error){ if destinationPath == "" { destinationPath = "." } if _, err := os.Stat(destinationPath); err != nil { if os.IsNotExist(err) { if err := os.MkdirAll(dir, 0777); err != nil { return "", errors.New("error creating destination directory: " + err.Error()) } }else{ return "", errors.New("error checking destination directory: "+err.Error()) } } return destinationPath, nil }
Step#2 - Find out the size of the file at the given URL and check whether it supports partial downloads or not
- An HTTP HEAD method is a way to find the size of the file and also to verify the partial downloads support of the destination file without actually downloading it.
- HEAD method
- It is one of the methods supported by HTTP.
- It is like the
GETrequest but fetches only the headers without the response body. - It is idempotent and safe.
- We can find the size of the file(in bytes) by reading the Content-Length header.
- To check whether the URL supports partial downloads or not, we have to check the Accept-Ranges header. Accept-Ranges header is set with
bytesif the URL supports partial downloads.
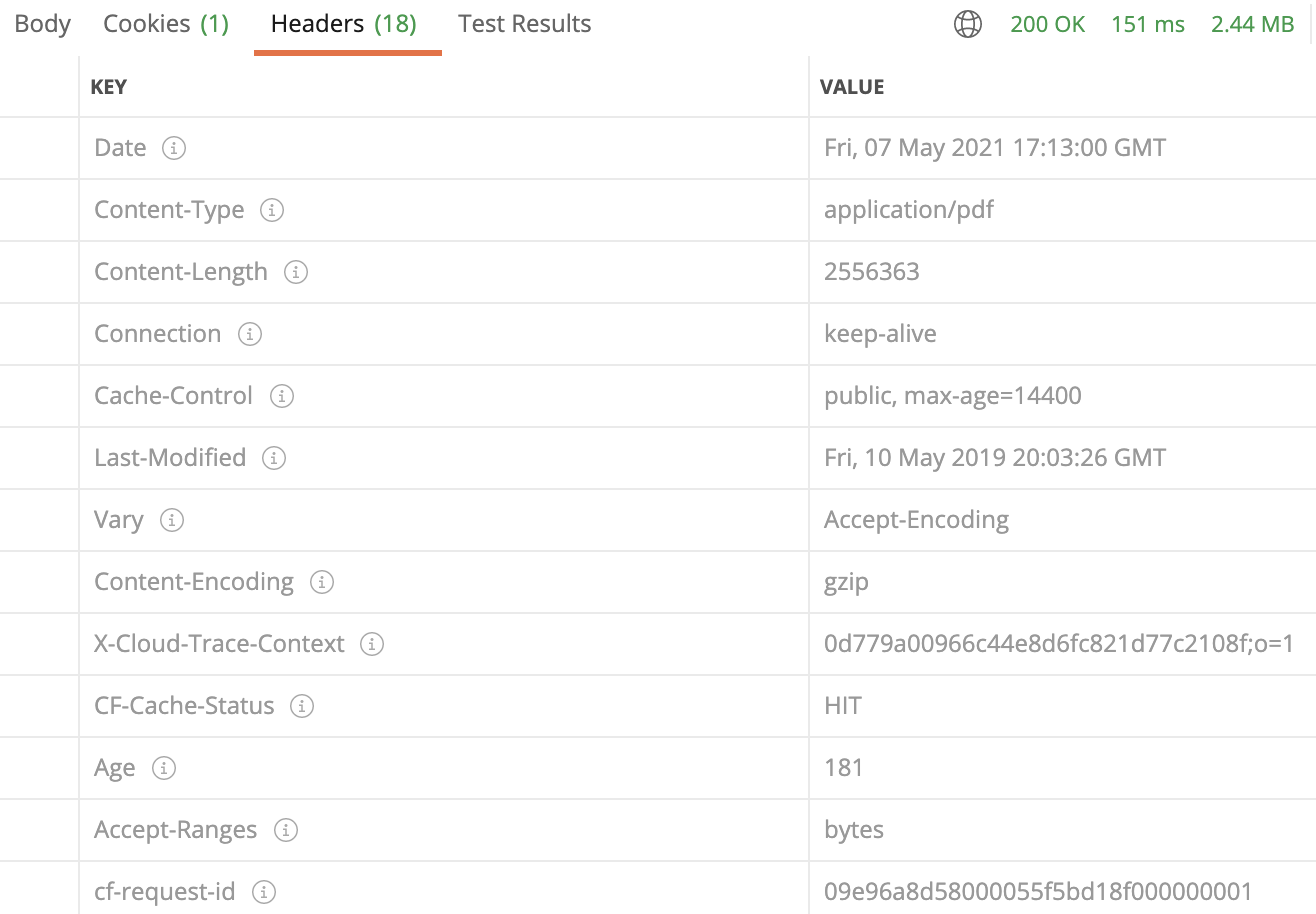
Result of the HEAD request for the URL(http://www.golang-book.com/public/pdf/gobook.pdf) is shown in the below image. The value of Content-Length header is 2556363(~2.5MB) which is the size of the file to be downloaded and Accept-Ranges is bytes which means the URL supprts partial downloads.
Step#3 - Determine the name of the downloadable file
- HEAD request may also provide Content-Disposition header in the response.
- Content-Disposition is the header that indicates whether the content is expected to be displayed in the web browser(Value of the header is
inline) or to be downloaded as a file(Value of the header isattachment; filename="filename.jpg"). - If
Content-Dispositionheader is present and its value isattachmentthen the filename can be extracted fromfilenameparameter if it is present. - If the above step doesn’t work, we should try to extract the filename from the given URL if it exists.
- If filename is present in the URL, then it is the last element in the given URL.
gobook.pdfis the name of the file in the given URL(http://www.golang-book.com/public/pdf/gobook.pdf).
- If we still can’t figure out the filename from the above steps, then return an error with the following message(
filename can't be determined).
func guessFilename(resp *http.Response) (string, error) {
filename := resp.Request.URL.Path
if cd := resp.Header.Get("Content-Disposition"); cd != "" {
if _, params, err := mime.ParseMediaType(cd); err == nil {
if val, ok := params["filename"]; ok {
filename = val
}
}
}
filename = filepath.Base(path.Clean("/" + filename))
if filename == "" || filename == "." || filename == "/" {
return "", errors.New("filename couln't be determined")
}
return filename, nil
}
Step#4 - Save the checksum and digest algorithm
- If we are not using a secure(
HTTPS) connection, it is possible that the downloadable file can be changed by any middleman. - We can use the checksum and the digest algorithm from Digest header to verify whether data from the server is the same as the data received by the client.
- Let’s save the checksum and the digest algorithm from Digest header if it is present and will use them in Step#7.
Step#5 - Decide whether to download from scratch or resume a partial download
- Check whether the downloadable file identified in Step#3 exists or not at the given location.
- If it isn’t present
- We have to start the download from the beginning by sending the GET request to the given URL.
- If the request is successful, we will receive 200 OK.
- If it is present
- Determine the file size(
existingFileSize) and download the rest of the file from theexistingFileSizebyte onwards. - We can send GET request by setting Range header as follows:
Range: bytes=existingFileSize- - If the request is successful, we will receive 206 Partial Content.
- Determine the file size(
- In both cases, we have to read the response body and copy it to the destination file.
func sendRequest(filename, URL string) (*http.Response, error) {
existingFileSize, err := getFileSize(filename)
if err != nil {
return nil, err
}
client := http.Client{}
request, err := http.NewRequest("GET", URL, nil)
if err != nil {
return nil, err
}
if existingFileSize > 0 {
request.Header.Set("Range", fmt.Sprintf("bytes=%v-", existingFileSize))
}
resp, err := client.Do(request)
if err != nil {
return nil, err
}
if resp.StatusCode == http.StatusOK || resp.StatusCode == http.StatusPartialContent {
return resp, err
}
return nil, errors.New(fmt.Sprintf("Unexpected Status Code:%v", resp.StatusCode))
}
func getFileSize(filepath string) (int64, error) {
var fileSize int64
fi, err := os.Stat(filepath)
if err != nil {
return fileSize, err
}
if fi.IsDir() {
return fileSize, nil
}
fileSize = fi.Size()
return fileSize, nil
}
Step#6 - Copy the data from the response body and write it to the destination file
- If the destination file doesn’t exist already.
- We already created the destination folder in Step#1 and figured out the filename in Step#3.
- In this case, we have to open the file in
os.O_CREATE(create a new file if none exists.) andos.O_WRONLY(open the file write-only.) mode.
- If the destination file already exists
- In this case, we have to open the file in
os.O_APPEND(append data to the file when writing.) andos.O_WRONLY(open the file write-only.) mode. - Seek to the end of the file where append has to begin.
- In this case, we have to open the file in
- Create a temporary buffer of any size(Ex:32 KB) to read the data from response body.
- Repeat the following steps until we receive
EOF(End of File) from response body.- Read the data from response body to the temporary buffer.
- Write the data from the buffer to the destination file.
- Increase the number of bytes written atomically which can be used to track the progress in main file.
func copyFile(filepath string, resp *http.Response) error { // Set the flag based on the existance of the file flag := os.O_CREATE | os.O_WRONLY fi, err := os.Stat(filepath) if err == nil { if fi.Size() > 0 { flag = os.O_APPEND | os.O_WRONLY } else { flag = os.O_WRONLY } } // Open the file fWriter, err := os.OpenFile(filepath, flag, 0666) if err != nil { return err } // Move to the end of the file if some data is already downloaded whence := os.SEEK_SET if fi.Size() > 0 { whence = os.SEEK_END } _, err = fWriter.Seek(0, whence) if err != nil { return err } // Create an empty buffer buffer := make([]byte, 32*1024) var written int64 for { // Read the data from resp body to buffer nr, er := resp.Body.Read(buffer) if nr > 0 { // Write the buffer to Destination file nw, ew := fWriter.Write(buffer[0:nr]) if nw > 0 { written += int64(nw) //Note: We can send this number of bytes written to main go routine using a shared value for logging download progress } if ew != nil { return ew } if nr != nw { return io.ErrShortWrite } } if er != nil { if er == io.EOF { break } return er } } return nil }
Step#7 - Compute and Compare the checksum
- If we are using
HTTPS, we don’t have to compare the checksums because the connection is secure(TLS). - If we are not using
HTTPS, we have to calculate the checksum of the downloaded file using the digest algorithm(retrieved in Step#2) and compare it with the original checksum(retrieved in step#2). - If they match, it means the downloaded data is the same as the data on the server. Otherwise, remove the downloaded file and return an error.
- Note:
- If we are not using a secure connection then it is possible that the middleman might have corrupted both the data(GET request) and the headers(HEAD request). So, comparing checksums is not going to help. Please find the corresponding discussion here.
- Step#4 and Step#7 might not be useful irrespective of whether we are using the secure or insecure connection but I am gonna keep them since they are good topics to understand.
- You can learn more about the checksum header here.
Additional Improvements
- Downloading the different parts of the file in parallel can improve the performance.
- To avoid file corruption, it’s better to check whether the remote file is updated or not before resuming partial downloads.
Conclusion
In this blog post, we have taken a quick look at the internals of a download manager. We also explored some of the HTTP features like HEAD method and headers like Content-Length, Accept-Ranges, Content-Disposition, Digest, and Range which we don’t frequently use in our day to day work.