on
Summary of Tail At Scale Paper
Every day we interact with a lot of web services like Google, Netflix, Instagram, etc. For example, Google responds with search results very quickly to user input while processing terabytes of data spanning over a lot of servers. We would love to use such web services because of their responsiveness. But It is challenging for the service providers to keep the tail latency short when the size and complexity of the system scale up or overall use increases.
What is Tail Latency?
- It is quite literally the tail end of the response time distribution graph
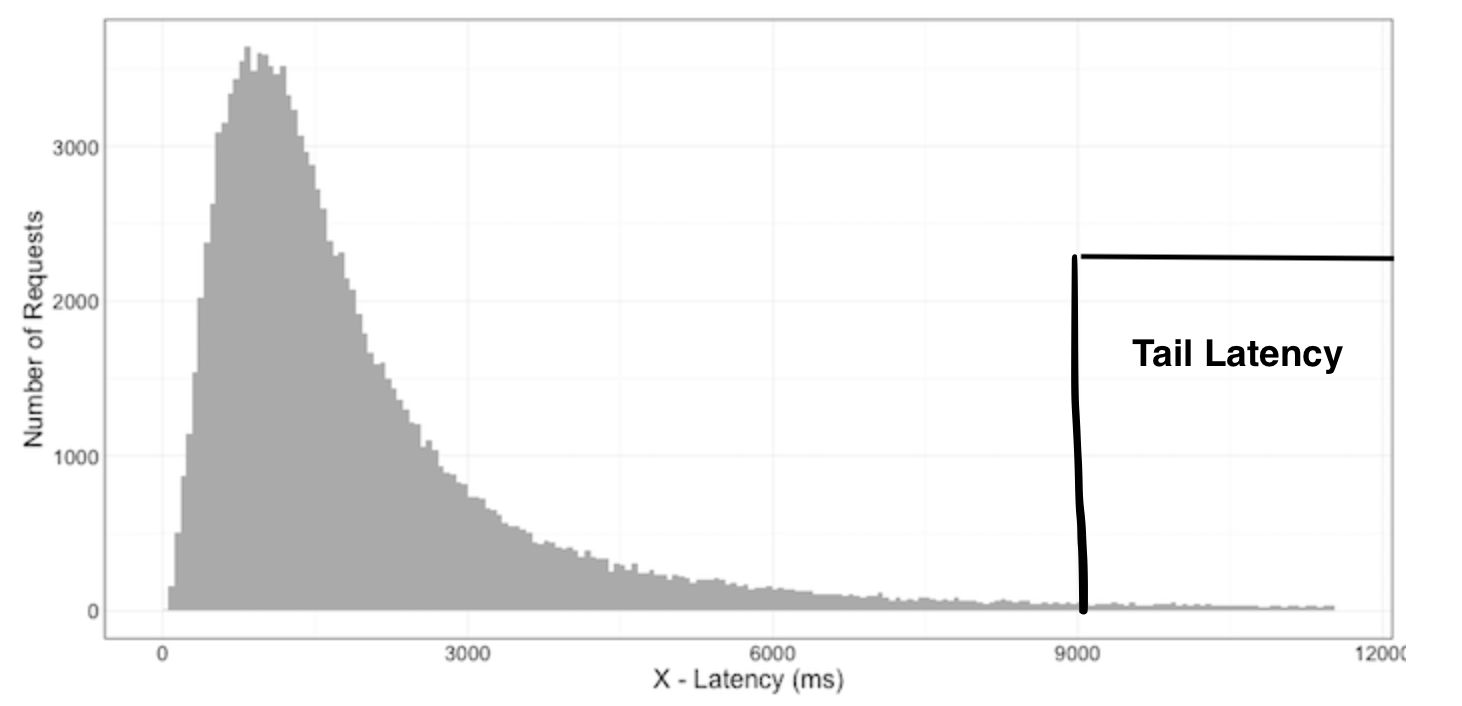
- In general, we consider the last 1% of response times or 99%ile of response times as Tail latency
- If the 99%ile of response times is 100ms. It means out of 100 requests one request took 100ms
Why is it important to reduce Tail Latency?
- For example, consider a web service that typically responds in 10ms but its 99%ile latency is more than 1 sec
- If the user request is handled by one server, one out of 100 requests will take more than 1 sec
- If the user request must collect responses from 100 such servers in parallel, then 63 out of 100 requests will take more than 1 sec
- Explanation
- Because all servers are running in parallel, even if one server takes more than 1 sec. Overall latency will be more than 1 sec.
- What is the probability of user request takes more than 1 sec?
Just as fault-tolerant computing aims to create a reliable whole out of less-reliable parts, large online services need to create a predictably responsive whole out of less-predictable parts
Why Latency Variability exists?
- Shared Resources
- Machines might be shared by different applications contending for shared resources
- Different requests within the same application might contend for resources
- Daemons
- Background jobs (like purging old data) or batch jobs might consume resources whenever they are running which can affect the real-time traffic
- Global Resource Sharing
- Services running on different servers in the same network might contend for global resources such as Network Switches, Shared File systems, etc
- Maintainance Activities
- Background activities (such as log compaction in storage systems like BigTable, Data reconstruction in Distributes File Systems, Periodic Garbage collection in garbage-collected Languages) can cause spikes in latency
- Queueing
- Multiple layers of queueing in intermediate servers (Network Buffer), Network Switches can amplify variability
- Power Limits
- Increased variability is also due to hardware trends such as CPU throttling
- CPU throttling is a technique in computer architecture which dynamically adjusts the frequency of CPU to reduce the heat generated by Chip
Reducing Component Variability
- Differentiating service classes (Prioritizing Requests)
- Prefer interactive requests over scheduled non-interactive requests
- Reducing head-of-line blocking
- Breaking long-running requests into a sequence of smaller requests to allow interleaving of execution of other short running tasks
- Ex: Converting computationally expensive query(query with large date range) into a number of concurrent cheaper queries(query with small date ranges)
- Managing background activities
- Triggering background activities at the time of lower overall load is often able to reduce latency spikes on interactive requests
While effective caching layers can be useful, even a necessity in some systems, they do not directly address tail latency
Living with Latency Variability
- The techniques presented in the previous section are essential but not sufficient to remove all kinds of latency variability
- So, Google has developed tail tolerant techniques that mask or work around the temporary latency pathologies, instead of trying to eliminate them altogether
- They separated those techniques into two classes
- Within Request Immediate-Response (Short-Term) Adaptations
- Cross Request Long-Term Adaptations
Cross Request Long Term Adaptations
- Cross request tail tolerant techniques examine recent behavior of the system by collecting statistics and then take action to improve the latency of future requests
- Static assignment of a single partition to a single machine is not sufficient for two reasons
- When a particular item becomes popular and load on its partition increases (Data induced load imbalance)
- Performance of the underlying machine is neither uniform nor constant over time
- Fine-grained dynamic partition (micro partitions)
- To mitigate Data Imbalance, Google divides the datasets into more partitions than the available machines for the service
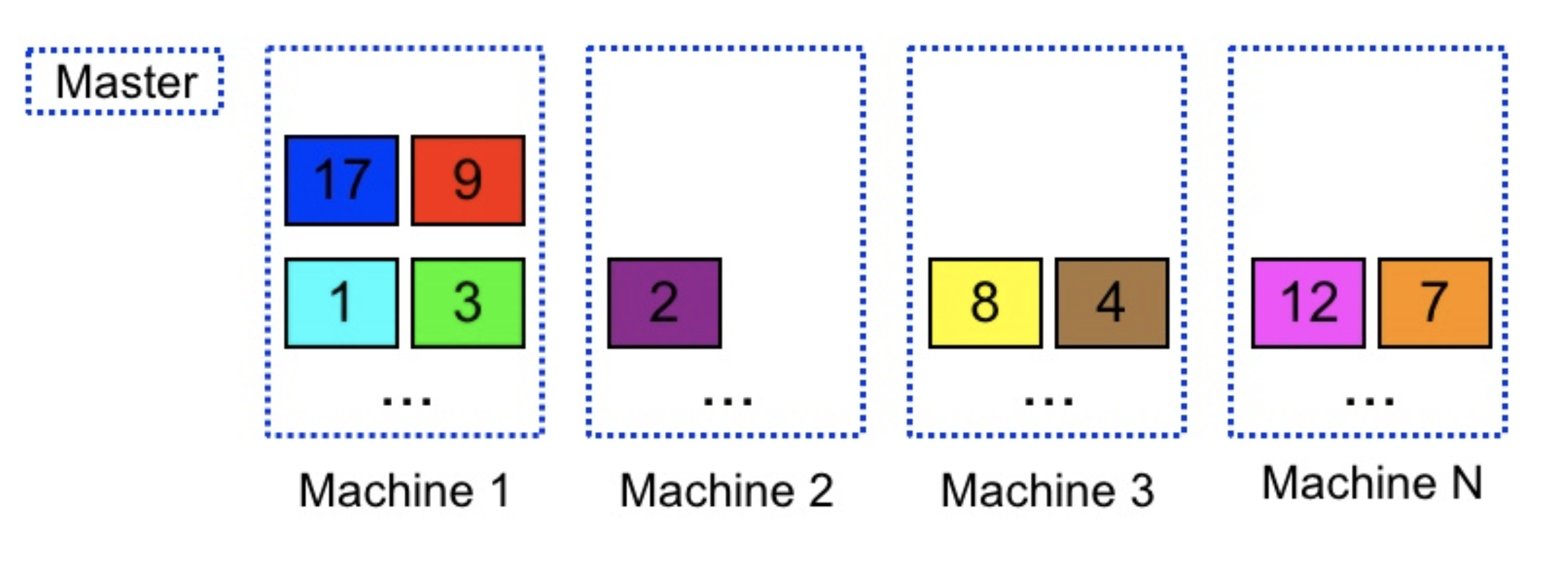
- Then dynamically assigns and load balances the partitions to machines
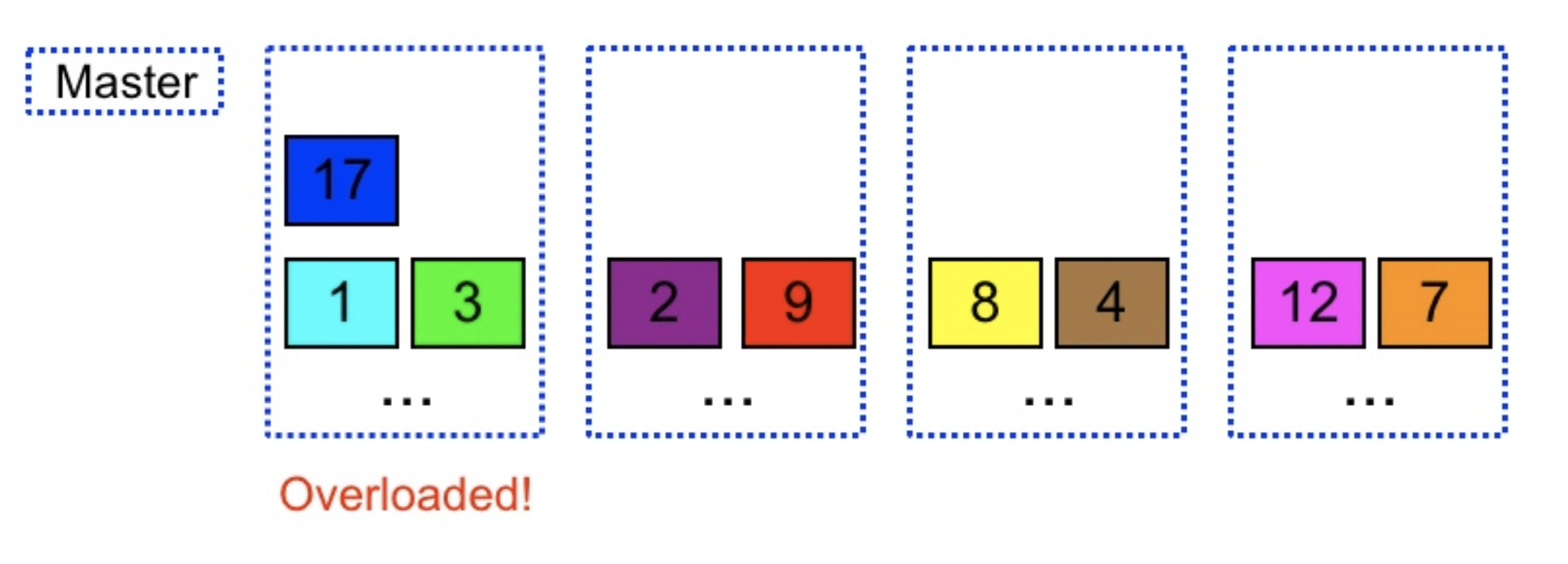
- Can shed load in small percent increments
- When one of the machines gets overloaded, we can dynamically shift few partitions from overloaded machine to other machines
- In the below image, when the first machine is overloaded, partition 9 is shifted to the second machine to reduce the load on the first machine
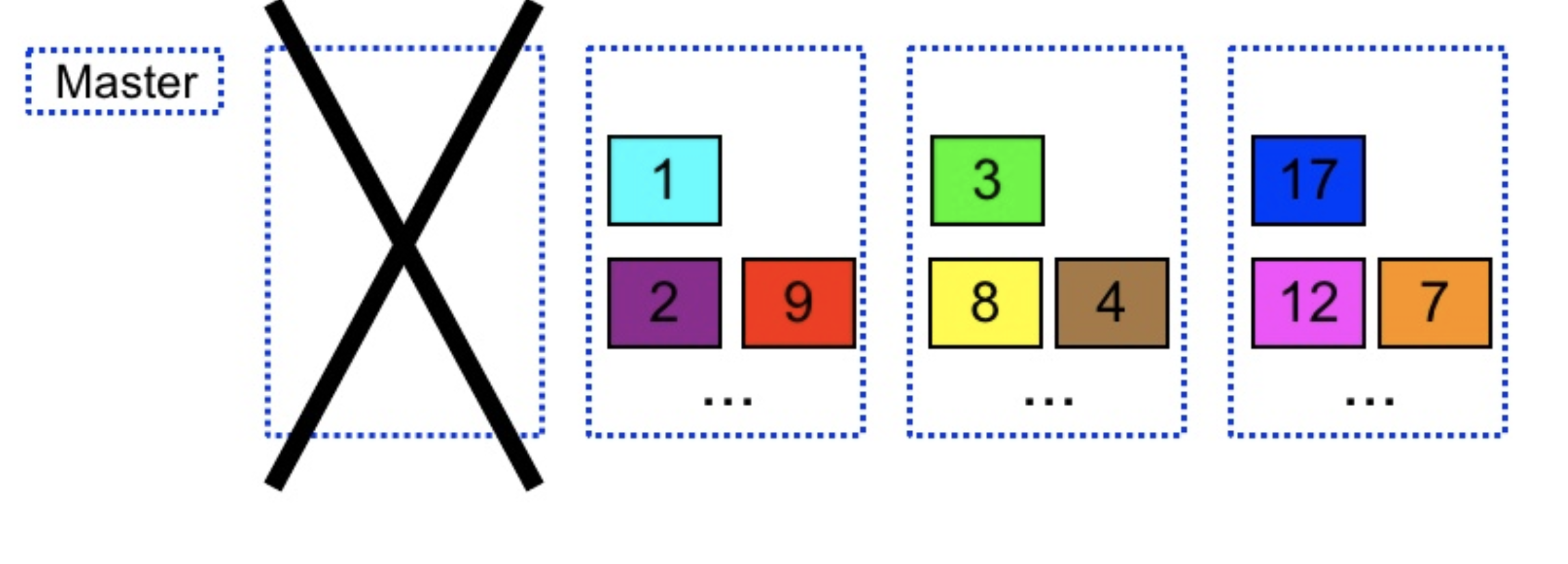
- Speeds Failure Recovery
- When one of the machines dies, other machines recover those partitions in parallel which speeds up the failure recovery
- In the below image, when the first machine dies, other machines recovered its partitions
- Selective Replication
- In this technique, Google tries to predict the items that are likely to cause load imbalance and creates additional replicas of those items
- Load balancing will take care of distributing the load of hot micro partitions among its replicas
- Latency Induced Probation
- Servers sometimes become slow to respond because of several reasons such as a spike in CPU activity because of some other job on the machine
- This technique suggests to remove slow machines from taking traffic and put them on probation
- Meanwhile, issue shadow requests to the machines on probation to measure the latency and bring them back into service when their latency is back to normal
- It seems non-intuitive but it actually improves latency during the period of high load
Within Request Immediate-Response (Short-Term) Adaptations
- Within request tail tolerant techniques try to mitigate the effects of the slow subsystem in the context of a high-level request
- Web services deploy multiple replicas of data items to increase throughput capacity and to improve availability in case of failures
- Following techniques uses replication to reduce latency variability within a single higher-level request
- Hedge Requests
- A simple way to reduce the latency variability is to send the same request to multiple replicas and use the result from whichever replica responds first and cancel the outstanding requests once we receive the response
- A drawback of this naive approach is an unacceptable additional load
- One approach which adds a small percentage of additional load is to send the secondary requests only after the primary request is outstanding for 95%ile expected latency. Google termed such requests as Hedge requests
-
For example, in a Google benchmark that reads the values for 1,000 keys stored in a BigTable table distributed across 100 different servers, sending a hedging request after a 10ms delay reduces the 99.9th-percentile latency for retrieving all 1,000 values from 1,800ms to 74ms while sending just 2% more requests
- Tied Requests
- In Hedge requests technique, multiple servers may execute the same request unnecessarily
- A simple form of tied request is to send the request to two different servers each tagged with the identity of the other
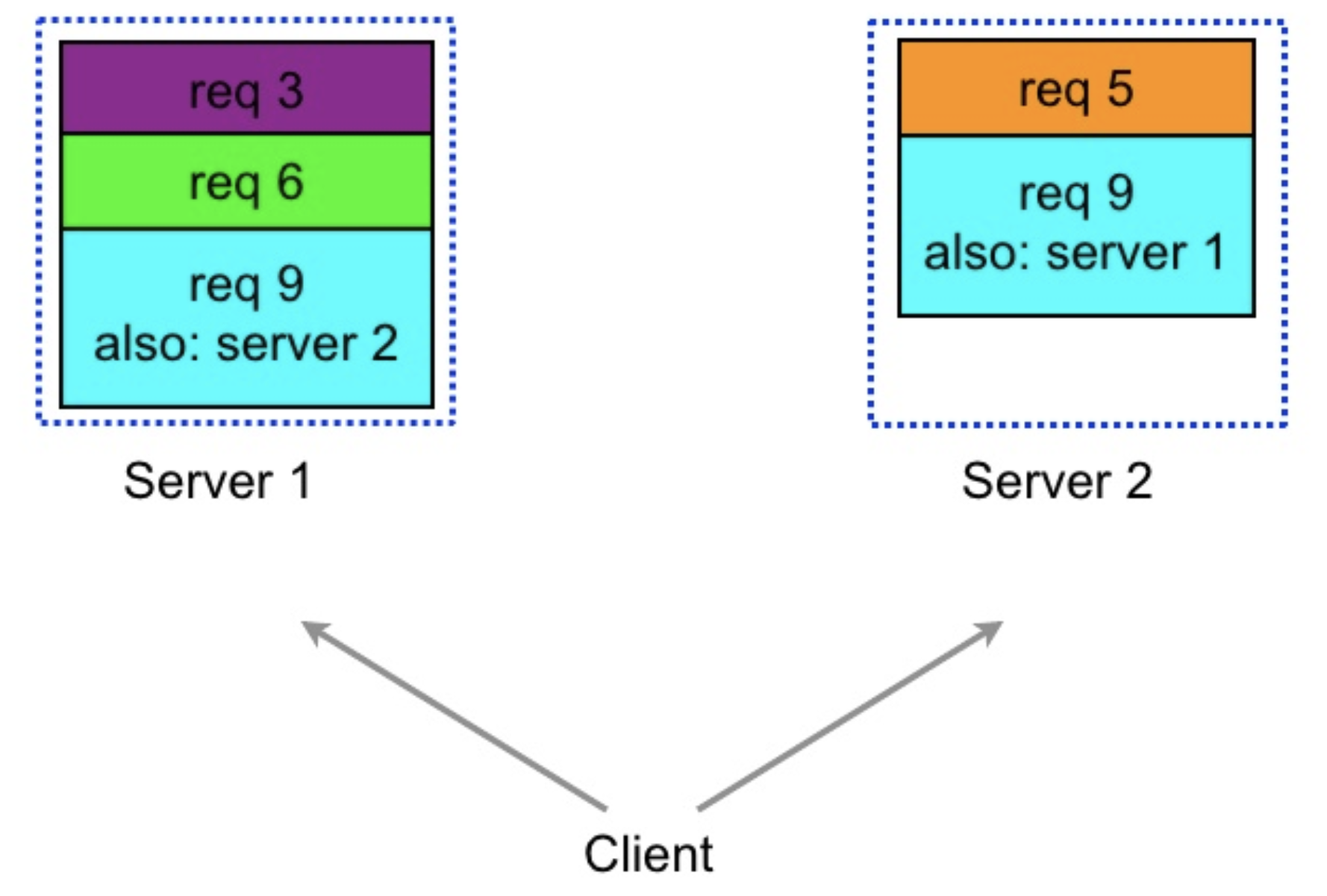
- When one of the servers picks up the request for execution, it sends the cancellation request to the other and other server removes the request from its queue
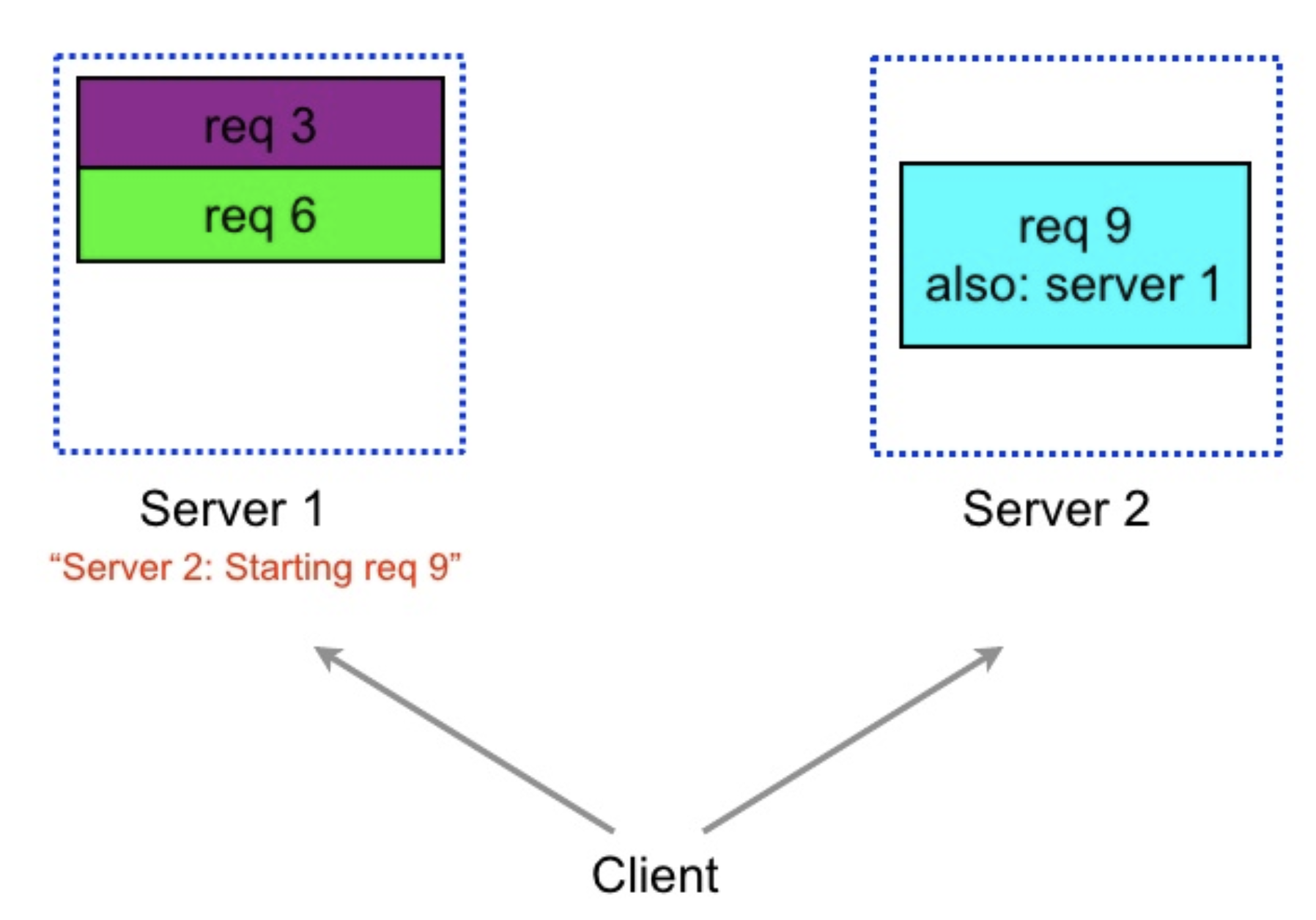
- Corner Case
- When both servers pick the request for execution while cancellation requests are in transit
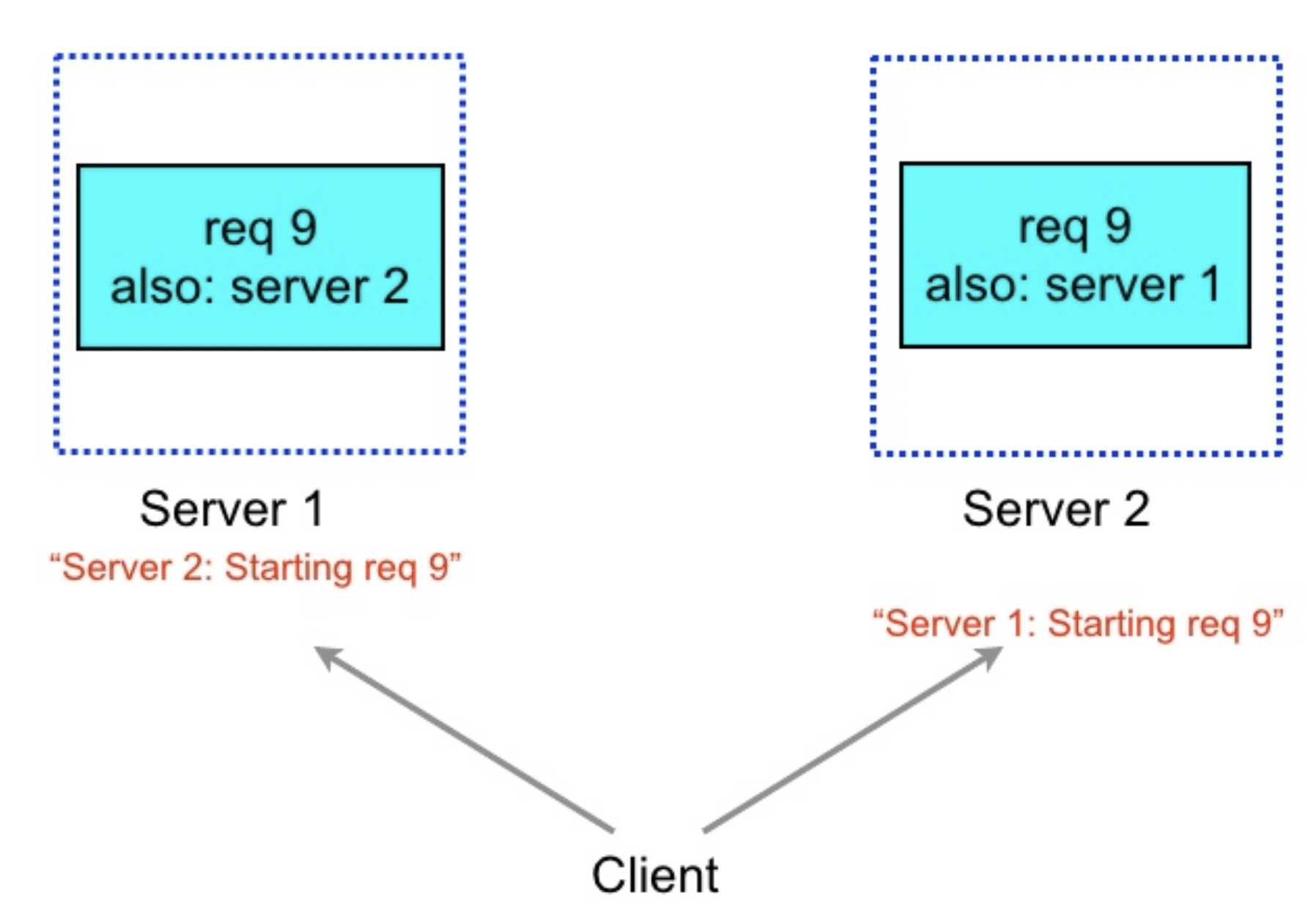
-
It is useful therefore for the client to introduce a small delay of two times the average network message delay (1ms or less in modern data-center networks) between sending the first request and sending the second request
- Tied Request Performance on BigTable
- Benchmark tests were run on Idle server and server with a concurrent background job
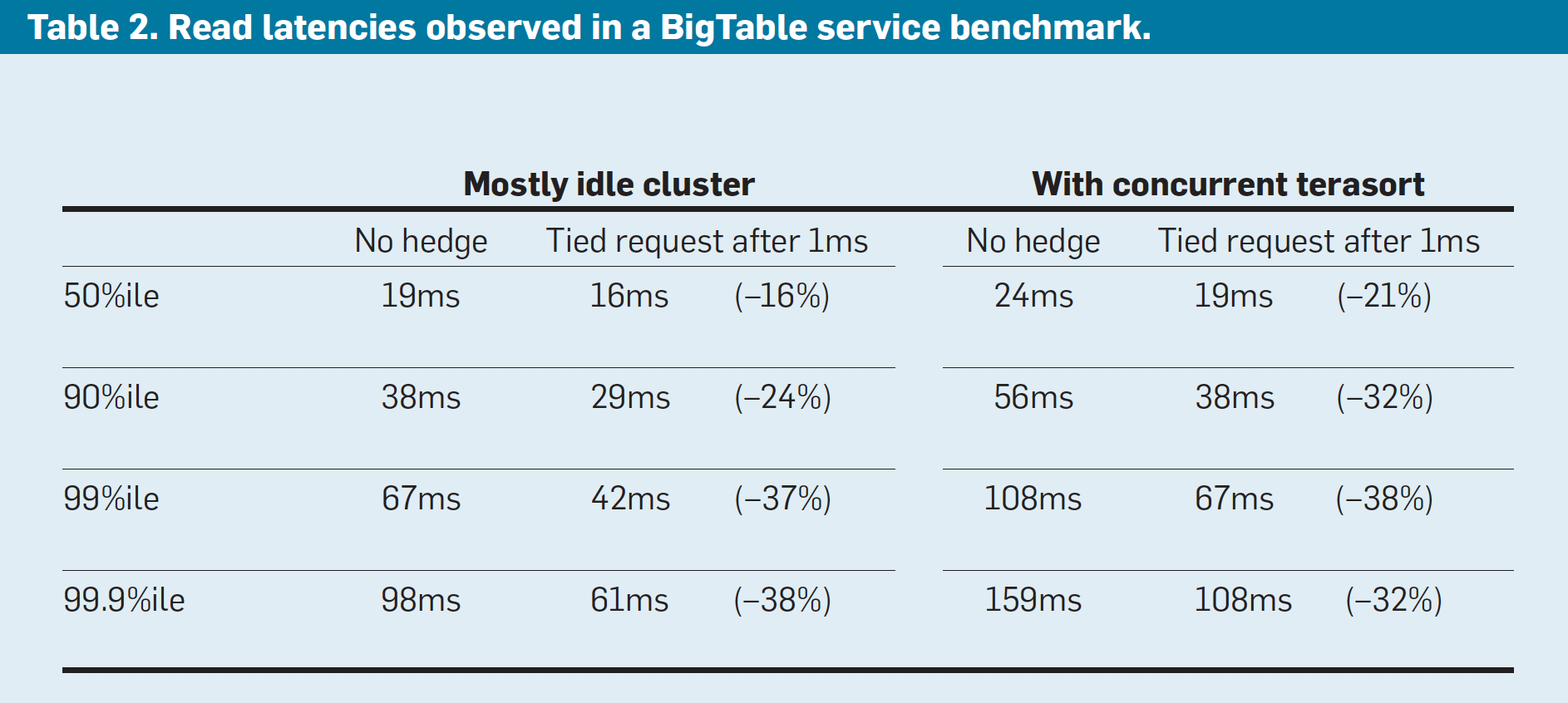
-
In the first scenario, sending a tied request that does cross-server cancellation to another file system replica following 1ms reduces median latency by 16% and is increasingly effective along the tail of the latency distribution, achieving nearly 40% reduction at the 99.9th-percentile latency
-
In the second scenario, overall latencies are somewhat higher due to higher utilization, similar reductions in the latency profile are achieved with the tied-request technique discussed earlier
-
In both cases, the overhead of tied requests in disk utilization is less than 1%, indicating the cancellation strategy is effective at eliminating redundant reads
- Remote queue probing
- In this technique, we first check the queues of servers to see which of them are less loaded and send the request to that server
- It is not as effective as the tied and hedge requests because of the following reasons
- Load levels can vary between probe and request time
- All clients can pick the least loaded server at the same time
- Request execution times are difficult to estimate
Large Information retrieval systems
- Good enough results
- Returning good results quickly is better than returning best results slowly
- When a sufficient amount of data is searched, return the results without waiting for the execution to complete
- Canary Requests
- Some times requests may exercise the untested code path which in turn may cause crashes or longer delays on thousands of servers simultaneously
- To prevent such scenarios, Google’s IR system uses a technique called Canary Requests
- In this technique, instead of sending the request to thousands of servers, the root server sends the request to only one leaf server
- If the root server receives the successful response from that server, then only it will send the same request to all leaf servers
- Canary request adds a small amount of latency because the system waits only for one server to respond
Mutations
- Some of the techniques discussed so far are not suitable for requests which make changes on the server-side
- For example, write requests might get executed twice in case of Hedge Requests
- What should we do if shadow requests are write requests in case of Latency Induced Probation?
Conclusion
This paper tells us about the importance of tail latency when the size and complexity of the system scale up, about the causes of the latency variability, and also provided with proven tail tolerant techniques to reduce the overall latency of the system.